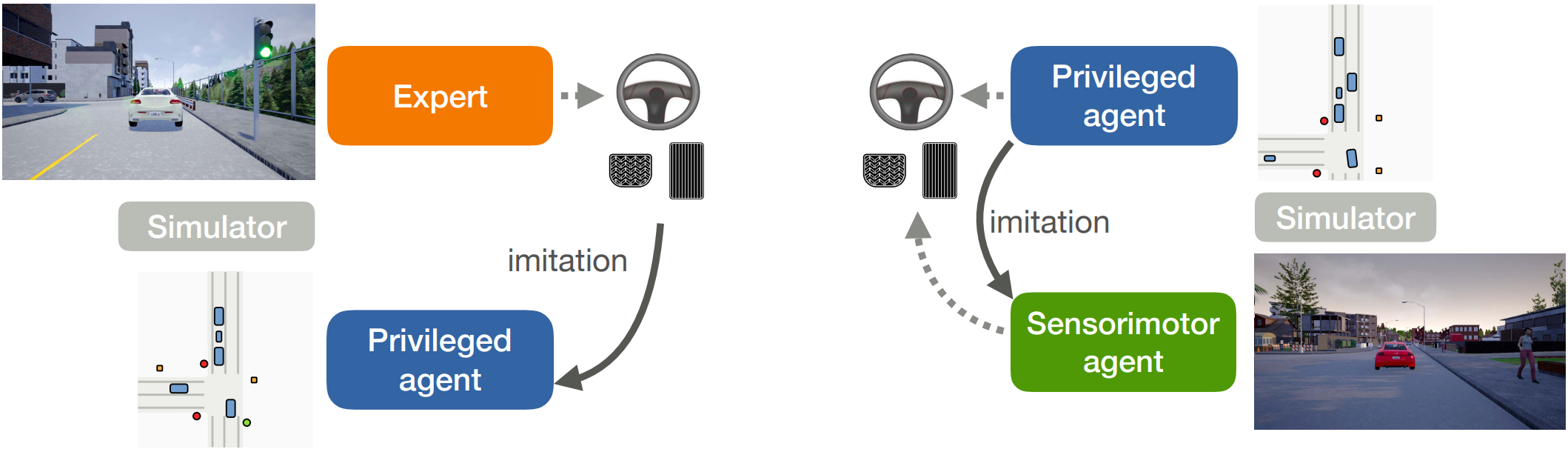
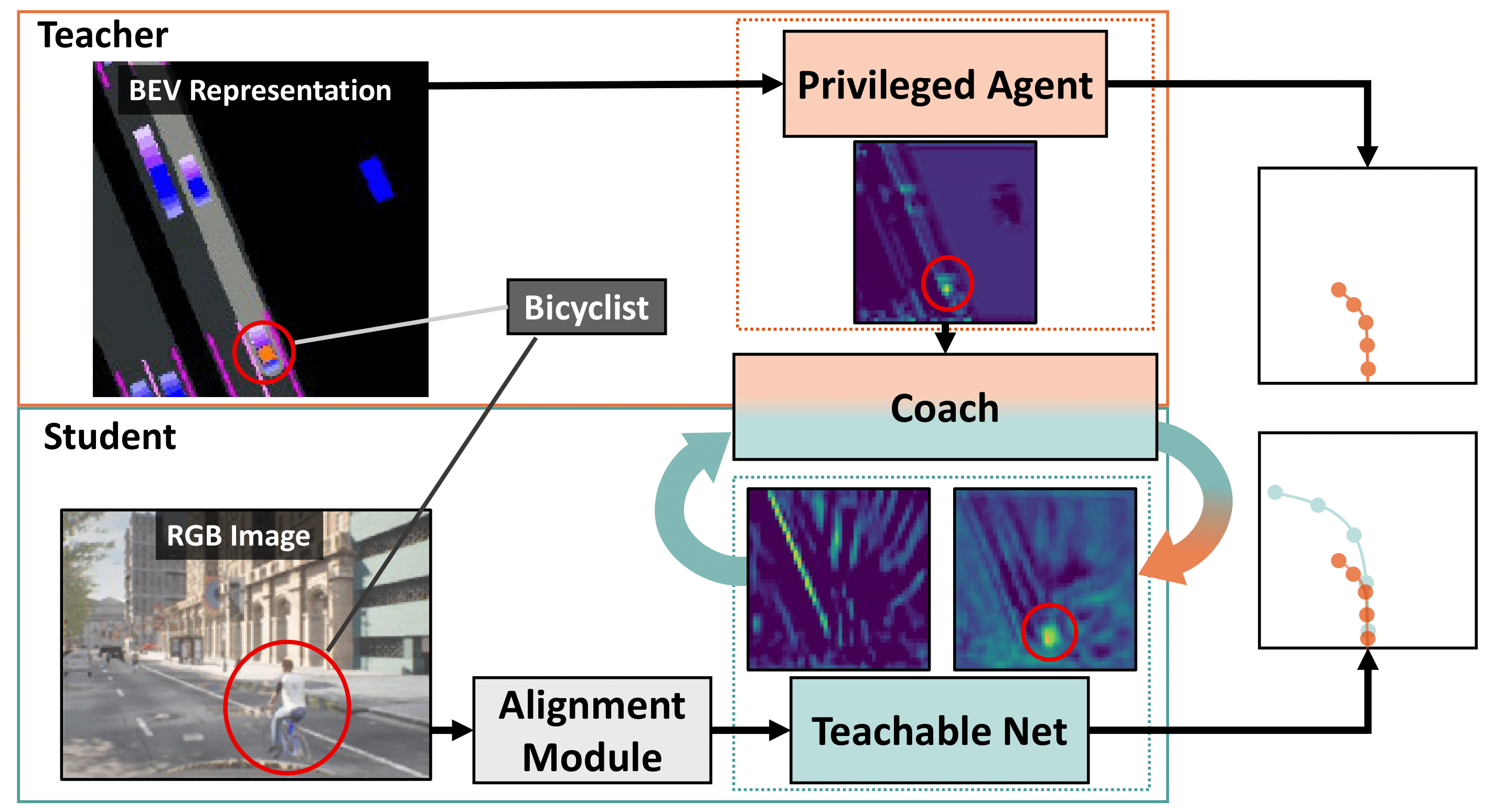
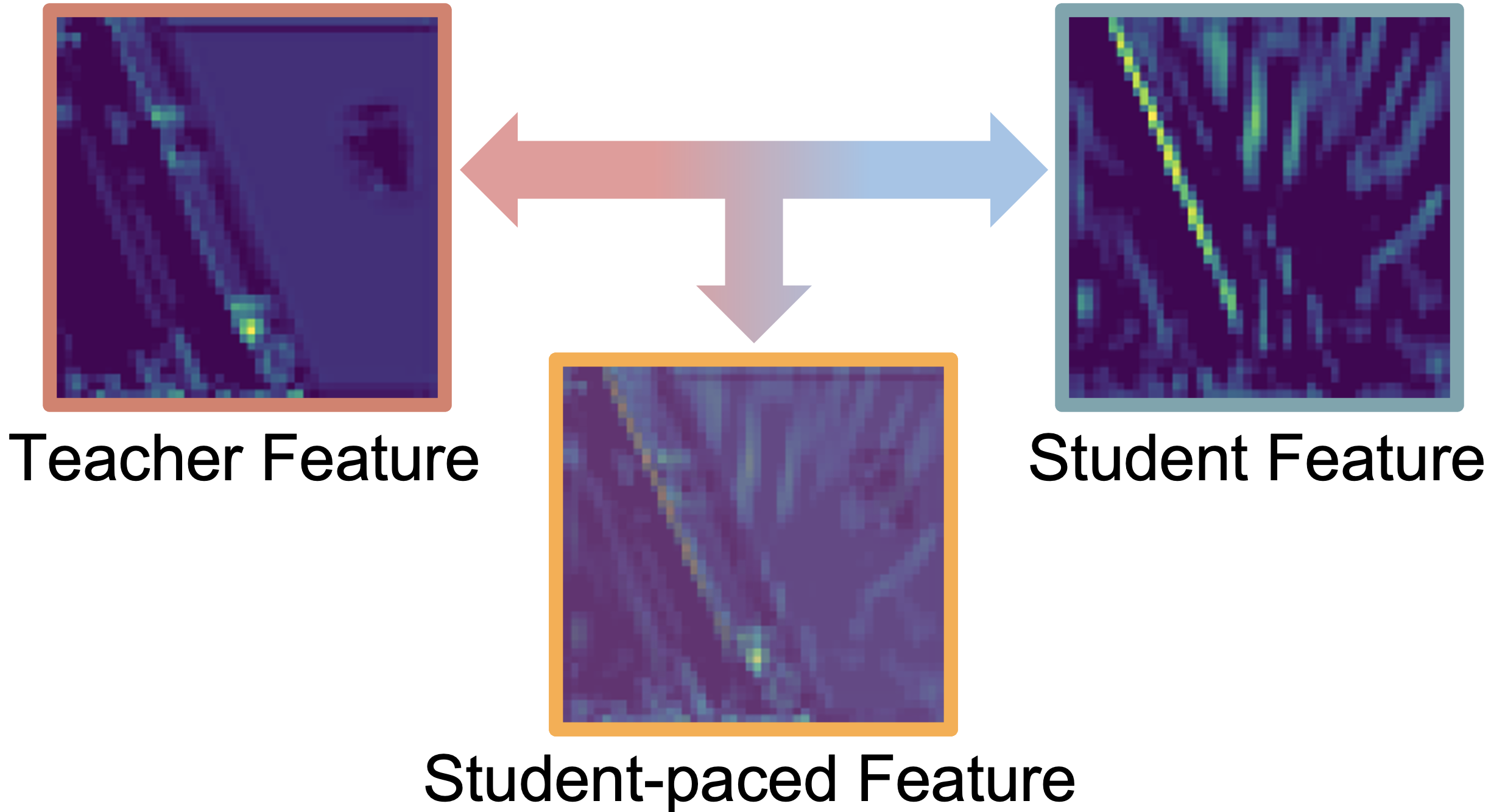
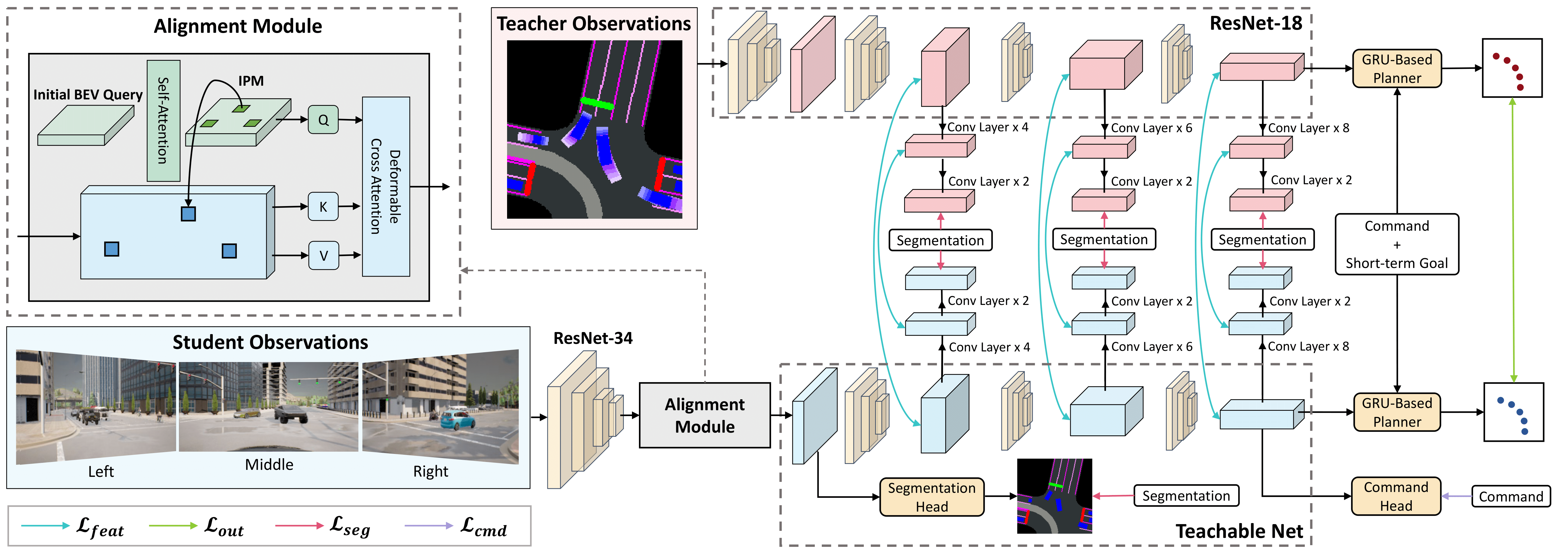
We propose a novel knowledge distillation framework for
effectively teaching a sensorimotor student agent to drive
from the supervision of a privileged teacher agent. Current
distillation for sensorimotor agents methods tend to result
in suboptimal learned driving behavior by the student,
which we hypothesize is due to inherent differences between
the input, modeling capacity, and optimization processes of
the two agents. We develop a novel distillation scheme that
can address these limitations and close the gap between the
sensorimotor agent and its privileged teacher. Our key insight
is to design a student which learns to align their input
features with the teacher’s privileged Bird’s Eye View (BEV)
space. The student then can benefit from direct supervision
by the teacher over the internal representation learning. To
scaffold the difficult sensorimotor learning task, the student
model is optimized via a student-paced coaching mechanism with
various auxiliary supervision. We further propose
a high-capacity imitation learned privileged agent that surpasses
prior privileged agents in CARLA and ensures the
student learns safe driving behavior. Our proposed sensorimotor
agent results in a robust image-based behavior
cloning agent in CARLA, improving over current models
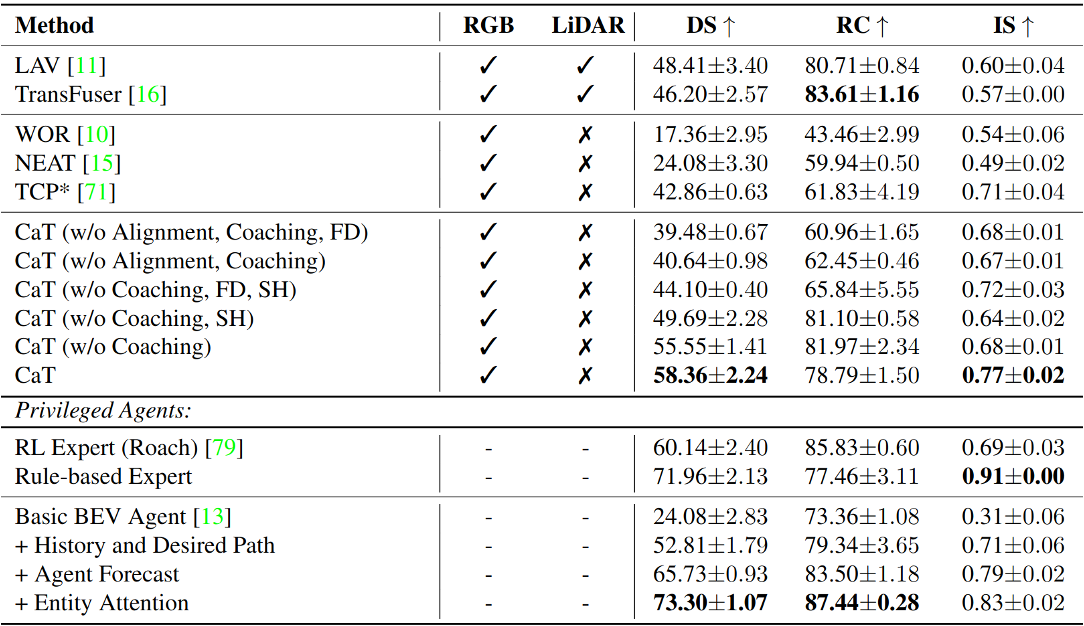
by over 20.6% in driving score without requiring LiDAR,
historical observations, ensemble of models, on-policy data
aggregation or reinforcement learning.